DeepESDL Services and Tools#
The Python xcube Toolkit plays a core role in the DeepESDL’s system design. Here we briefly introduce the key components of xcube to provide an overview.
The xcube generators are command-line tools used to generate analysis-ready data cubes (ARDC) with inputs from one or more data stores.
The xcube Server provides a web service that offers several RESTful APIs. It publishes collections of ARDCs which are provided by configurable data stores but also provides an OGC WMTS and time-series service.
The xcube Viewer is a simple and very easy-to-use single-page web application that fully exploits the APIs offered by xcube Server.
xcube Data Stores are used by the xcube Generator and the xcube Server represent different data cube sources.
Finally, the xcube Python API
provides various high- and low-level functions for
data analysis that operate on data cubes and comprises programmatic
access to all other xcube Components mentioned above.
Users call the Python API from their own programs, scripts, JNBs,
or from user code executed in the xcube gen2 generator.
During the project, generic functions will be added to the Python API
to support machine learning using the data cubes (see ML Toolkit below),
as well as new use case specific functions as desired in the
different DeepESDL user projects.
xcube Generators#
The command-line tools
xcube gen and
xcube gen2
offer flexible data cube generation
that is made available via a dedicated JupyterLab
profile. The tool reads data streams from one or more data stores,
then it resamples and combines them. The merged cube can then be
manipulated by user-provided Python code before the resulting
cube is written into another data store, for example AWS S3.
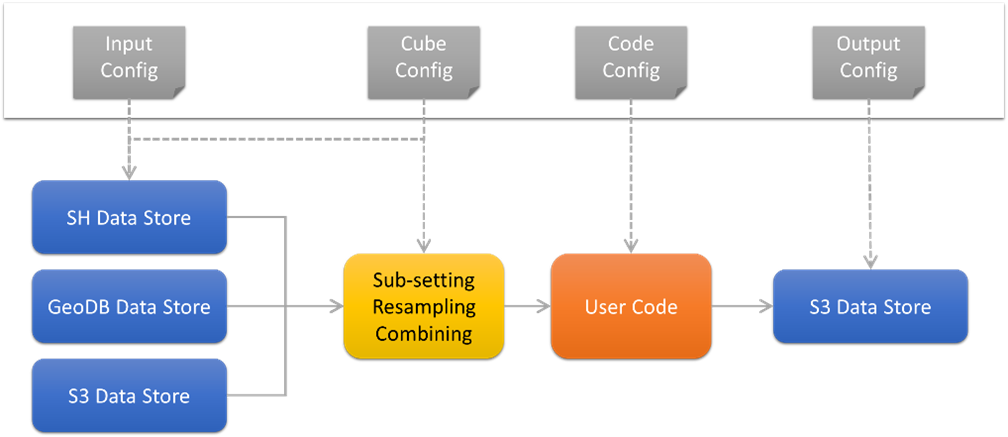
The current features of the xcube generation service are:
- Read data streams from a variety of xcube data stores (see xcube Toolkit).
- Perform spatial resampling of raw and rectified data streams to a common spatial grid using standard coordinate reference systems, e.g., EU LAEA (EPSG:3035).
- Perform temporal resampling by aggregating observations to equally sized time periods, e.g., 8-day averages.
- Merge resampled data streams into a single cube, optionally passing it to user Python code for further value adding or transformation.
- Write chunked data cube into remote object storage or the local file system.
xcube Server#
The xcube Server
(xcube serve)
offers a web service that publishes collections of
data cubes which are provided by configurable xcube data stores.
It offers a RESTful API for browsing the published cubes (catalogue),
for multi-resolution image tiles (OCG-compliant WMTS, later WCS),
for time-series retrieval, and for direct data access.
Moreover, it will be equipped with a STAC-compatible catalogue API that
supports spatial OpenSearch requests.
The xcube Server will be extended to fully support any new xcube Viewer features, for example linking the geoDB with xcube Server and Viewer.
xcube Viewer#
The xcube Viewer
(xcube-viewer)
is a simple and very easy-to-use single-page web application
that fully exploits the APIs offered by xcube Server. It displays the
spatial images of the data cubes on a map at given time steps,
it can show a variable’s time series with error bars for any geometry and
show the details of a data cubes and its variables.
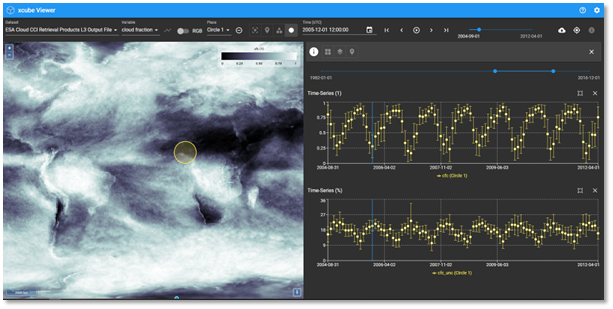
The xcube Viewer provides several useful tools to explore data cubes. For example:
- Open any number of data cubes and display spatial images of dataset variables on a map.
- Open places (vector data) associated with data cubes and display them.
- Show detailed information about selected data cubes, data variables and places.
- Select places or let users draw shapes and display time series with error bars.
- Click into time series to show corresponding images in map.
- Start a “player” that steps through time and animates the map and time
indicator in time series diagrams accordingly. - Download extracted time series data.
During the DeepESDL project, the xcube Viewer will be enhanced by new features such as:
- Switching between 2D map display and 3D globe displays.
- Multiple, possibly synchronized 2D/3D displays and split-view displays.
- Generate new data variables on-the-fly from user-supplied Python functions. Code may originate from shared locations on GitHub or may be provided inline by a simple code editor.
xcube Data Stores#
Data store implementations are dynamically registered in the xcube Data Store Framework. The following data stores are already available
- ESA CCI Open Data Portal (from xcube plugin xcube-cci).
- C3S Climate Data Store (from xcube plugin xcube-cds).
- CMEMS Data Store (from xcube plugin xcube-cmems).
- Sentinel Hub (from xcube plugin xcube-sh).
- Generic data stores such as S3-compatible object storage (
s3), local file system (file), and in-memory (memory).
Its is planned to develop data stores for the geoDB service, so users can retrieve vector datasets and rasterized vector data sources as gridded ARDCs. Other data stores that are needed by DeepESDL Projects will be added as required by specific use cases during the project.
ML Toolkit#
The DeepESDL ML Toolkit is a small and handy Python package that provides useful functions for machine learning tasks with DeepESDL data cubes.
The toolkit is made available as a DeepESDL JupyterLab environment (profile), and includes popular libraries such as scikit learn, TensorFlow, Keras, and PyTorch.
To support model evaluation during training, the ready-to-use processing environment is also extended by a TensorBoard to support the tracking of individual experiments and training runs. This tool can be used with PyTorch and TensorFlow, and it provides a state-of-the-art toolset for data scientist to inspect the tuning and training process and compare metrics.
The toolkit offers the following:
-
Adapters are provided to existing data loading and transformation mechanisms from Keras and PyTorch (
DataGenerator,DataLoader) to be usable for the DeepESDL data cubes. -
Implementations of sampling mechanisms and online repartitioning methods suited for the data cube files which are stored in chunks. This element is essential, as it enables deep learning that respects the basic principles of geo data way beyond naive applications of machine learning in the Earth system context.
To ease adoption by scientist we plan to also develop script templates for common deep learning tasks such as autoencoder on time-series data, in particular physics informed autoencoder, transfer learning and change detection on time series.
The toolkit is currently for Python only, but Julia will also be considered to address a small but growing community of data scientists.