DeepESDL Architecture#
The following figure depicts the high-level concepts and the architecture of the DeepESDL project. It comprises the internal DeepESDL Hub and user projects and the publicly visible parts. Both are served by a common infrastructure and common resources.
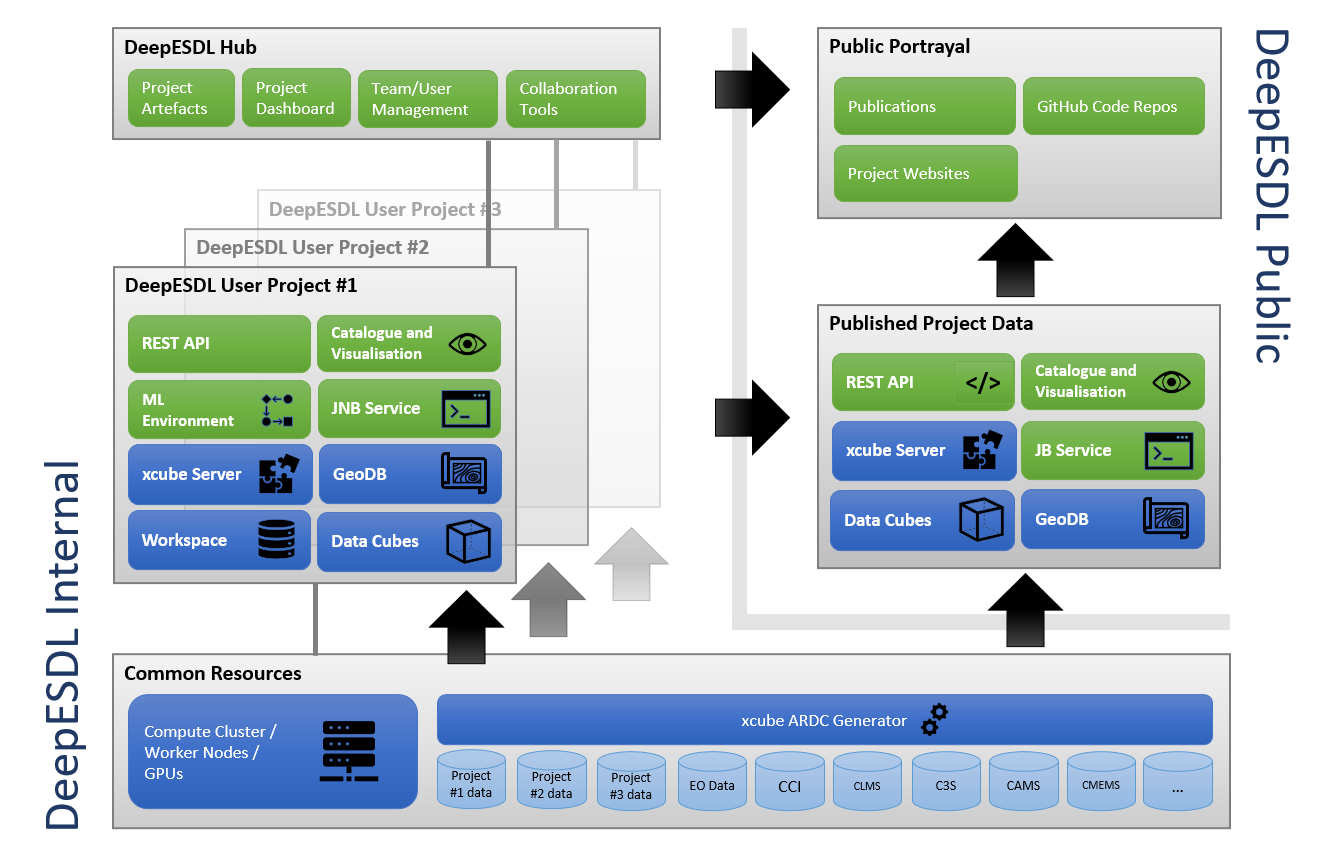
Applications available to users within DeepESDL comprise:
- An xcube Catalogue to browse available data, including a web page that lists available datasets as a low-barrier entry point for users. (In development, will be similar to the ESA EuroDataCube Collections.)
- Visualisation tools such as adapted versions of the xcube Viewer and a 4D Viewer.
- A Jupyter Notebook (JNB) service so that users can run Jupyter Notebooks with project-specific Machine Learning (ML) environments.
Services available to users within DeepESDL comprise:
- An xcube Server to browse, access, and publish gridded data cubes.
- A geoDB instance to browse, access, and publish vector datasets.
- A Workspace so projects can store and share any other data, such as ML workflows.
- Access to all shared and project-specific Data Cubes in object storage.
Each project has access to the DeepESDL common resources that comprise a cluster of worker nodes as well as a common xcube ARDC Service, that can access a variety of data access services and turns provided data into analysis-ready data cubes (ARDC). DeepESDL data cubes share a consistent structure and use a uniform format.
To enable efficient machine learning on data cubes, the ARDC Generator utilizes a configurable ML sampling module for training and validation. Likewise, the worker nodes offer GPU-acceleration for demanding ML training. Core libraries include Keras/Tensorflow and PyTorch and advanced tools for model evaluation like TensorBoard or MLflow are made available.
The DeepESDL Published Project Data is backed by a subset of the applications and services granted to each project, that is, a common xcube Server and geoDB is provided to serve the public catalogue and visualisation tools; a public REST API allows accessing the services programmatically. Public services will later also comprise a Jupyter Book (JB) or Notebook Viewer (NBviewer) service, so that selected Project-JNBs can be elaborated into published, story-telling books. This service together with catalogue and visualisations tools are important parts of the DeepESDL scientific information dissemination.
The numerous distributed services and applications of the DeepESDL system are containerized and are executed in a common cloud environment. To orchestrate, monitor, maintain, and scale the variety of DeepESDL services and applications, we use today’s most popular container orchestrator Kubernetes (K8s). This supports the idea that the DeepESDL system is deployable on any Cloud environment that can run a K8s service (this is, AWS, Google, Microsoft Azure, and many others including all DIAS instances). The initial system is deployed on Amazon Web Services (AWS) in the EU-Central-1 region, which is physically located in Frankfurt, Germany, Europe using the managed K8s service EKS, which is critical for cost-efficiency and reliability of DeepESDL.
To be able to meet the ambitious requirements for the service, we must base the solution mainly on existing technologies. Many of the DeepESDL system components have been developed in former (mostly ESA) projects and are thus reused, adapted, extended, and branded for DeepESDL. Examples are
- DeepESDL Hub is based on EOxHub developed by EOX and used for example in the ESA EuroDataCube project;
- The xcube cube generator tools, xcube Server, xcube Viewer are derived from already available components in the xcube Toolkit developed and used in several activities by the development team;
- The Cube 4D Viewer will be an adopted version of Earthwave’s 4D Viewer.